
기획자가 데이터를 분석하는 방법
서비스 기획자가 DB에 직접 접근해 데이터를 추출하기는 꽤 번거롭습니다. 그래서 회사에서는 누구나 데이터를 볼 수 있도록 데이터 시각화 툴을 개발하거나 다른 회사 솔루션을 돈을 내고 사용하죠. 저는 ES사의 데이터 시각화 툴인 키바나를 이용합니다. 원하는 모든 방식대로 시각화가 가능하진 않으므로 주로 엑셀로 추출해 2차 가공을 하지만, 비개발자도 쉽고 빠르게 데이터를 찾기에 적합한 툴입니다.
이번 글에서는 키바나를 사용해 추출할 수 있는 데이터와 추출 방법을 두 가지 사례로 알아보겠습니다. 회사마다 DB의 구조, 접근 권한, 사용하는 시각화 툴이 다르지만, 이 글을 읽으면 기획자에게 어떤 데이터가 필요한지, 그리고 어떤 방법을 사용하는지 알 수 있을 거예요. 서비스 기획 현직자라면 다른 기획자는 또 어떻게 데이터와 씨름하고 있나 보실 수 있을 거고요. :)
그럼 키바나가 어떻게 생긴 툴인지부터 빠르게 알아볼까요?
1. 사용하는 툴 (Kibana)
1) Discover 기능
데이터를 개괄적으로 볼 수 있는 화면입니다. 원하는 필드를 선택해 최근 데이터를 확인하기 편리합니다. 1) 인덱스 선택하기에서 보고 싶은 DB(테이블)의 일부를 선택합니다. 2) 그 후 해당 테이블에서 "날짜", "콘텐츠 제목"과 같이 보고자 하는 필드를 선택해 4번 영역에서 확인합니다. 3번 영역에서 필터를 걸거나 검색으로 추출할 데이터를 제한할 수 있습니다.
자세한 내용은 "2. Kibana로 분석한 데이터"에서 사례와 함께 알려 드릴게요.

2) Visualization 기능
데이터를 특정 방식으로 정리해 보고 싶으면 visualization 메뉴로 진입합니다.
먼저, 시각화 포맷을 선택합니다. 저는 주로 Data Table과 Verical Bar 형식을 사용합니다. 그 후 시각화를 할 데이터 소스를 선택합니다. Discover에서 저장한 파일을 찾아서 선택할 수 있습니다.

아래는 Vertical Bar 포맷을 선택한 모습입니다. Discover과 마찬가지로 필터를 걸고, 그래프의 가로축 세로축의 기준을 정할 수 있습니다. 저는 주로 날짜를 가로축에 두고 로그 합산 값을 세로축에 두어 담당한 서비스의 사용 로그 트렌드를 파악합니다.

2. Kibana로 분석한 데이터
사례 1) 메타 데이터 분석
DB에 저장된 데이터를 확인하는 방법입니다.
Q. 평점이 가장 높은 영화 제목을 내림차순으로 볼 수 있을까?
A.
1. Discover에서 콘텐츠명과 평점 column을 추가합니다.
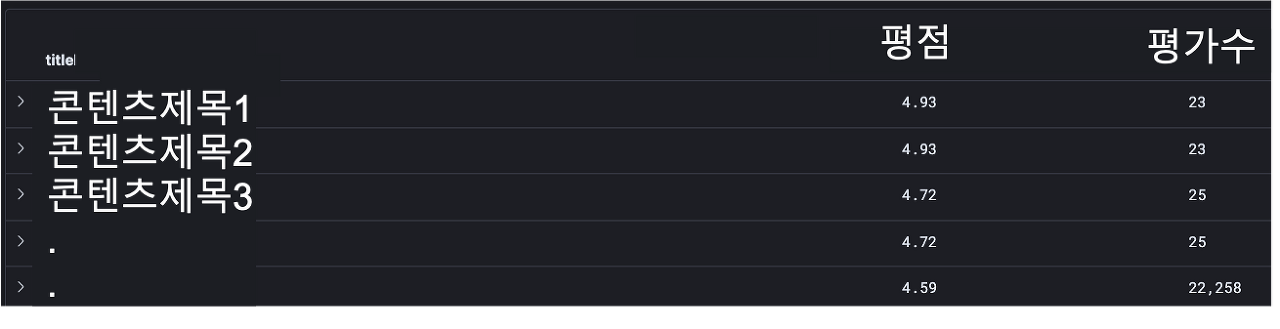
원하는 칼럼(필드)을 좌측 "available fields"에서 추가할 수 있습니다. 저는 평점과 평가수 필드를 선택했습니다. 그 후 평점 column을 내림차순으로 정렬합니다. 그런데 평가수가 너무 낮아서 평균 평점이 높은 콘텐츠가 상위에 있네요. 평가수가 20건 초과인 케이스만 필터링합니다.

2. 데이터를 확인합니다.
평가수가 20건 초과인 콘텐츠가 평점 내림차순으로 정렬되었습니다.
다만, 데이터 적재 기준이 콘텐츠명이 아닌 영상파일 ID입니다. 동일한 제목에 영상파일이 여러 개일 경우, 동일한 평점과 평가수가 두 차례씩 노출됩니다. 데이터를 엑셀 파일로 내려받은 후 콘텐츠 제목을 기준으로 피벗 테이블을 만들어 정리합니다.
사례 2) 사용자 로그 분석
사용자의 활동 내역인 로그 데이터를 보는 방법입니다.
Q. 최근 일주일간 출연진 정보가 가장 많이 클릭된 콘텐츠 top-5는?
A.
1. 출연진 정보를 찾는 방법을 모두 정리합니다.
예를 들어, 1) 영상 시청 중에 리모컨 상방향 버튼을 눌러 인물 정보를 확인할 수 있고, 2) VOD 재생 전 상세 정보 화면에서도 인물 정보를 볼 수 있습니다. 1)과 2)의 로그를 찾는 쿼리가 다르므로 (Query 1: "재생 중 인물 로그") or (Query 2: "상세 정보 화면 인물 로그")로 필터를 겁니다.

2. 기간을 설정합니다.
로그를 추출할 기간을 정합니다. 저는 주로 일주일 단위로 로그를 확인합니다.

3. <Buckets>에서 열을 추가합니다.
- 로그 취합 기준을 콘텐츠명으로 정하는 방법입니다.
- Buckets 하단의 "Add" 버튼을 누르고 "Split rows"를 클릭합니다.
- Sub aggregation은 "Terms"로 선택합니다.
- 정렬 기준(order by)을 원하는 측정값(metric)으로 정할 수 있습니다.
- Order을 "Descending"으로, Size 값을 5로 지정해 top-5의 콘텐츠만 확인합니다. 더 많이 보고 싶으면 Size를 늘려주세요.

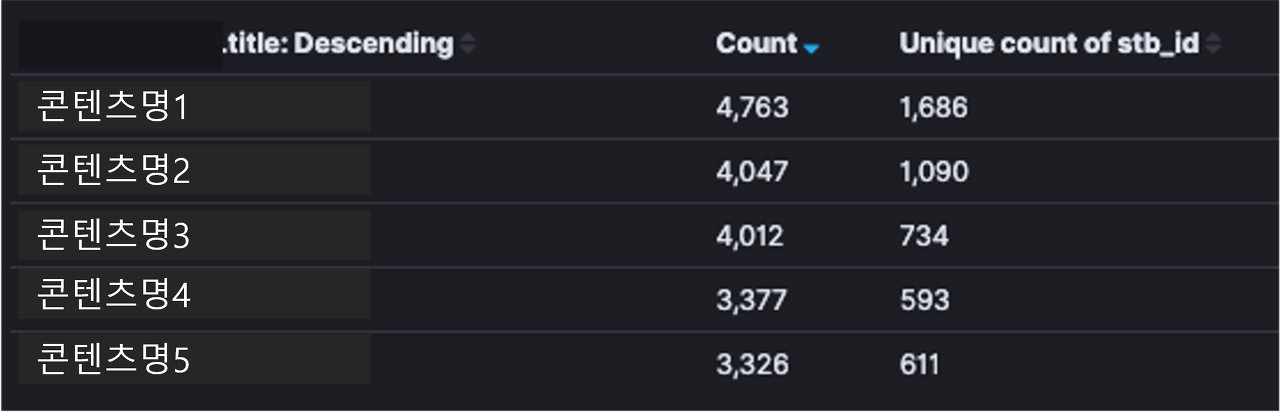
다 설정한 후 "Update"를 누르면, 아래와 같은 화면이 뜹니다. 인물 선택 로그가 top-5인 콘텐츠 제목이 순서대로 로그 값과 함께 나열됩니다.

4. <Metrics>에서 측정값을 추가합니다.
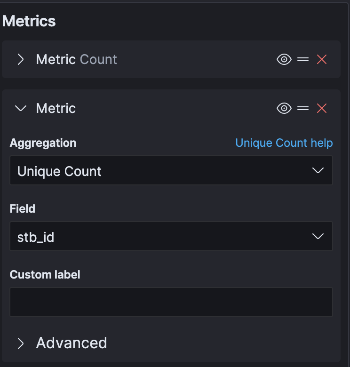
만약, 로그 합산이 아니라 UV(Unique Visitor) 값을 알고 싶다면, metric를 추가해야 합니다. Aggregation의 기준을 "Unique Count"로 정하고, Field에 카운트할 기준이 있는 필드를 선택합니다. 저는 셋톱 아이디를 사용자 한 명으로 보고 셋톱 아이디 필드를 선택했습니다.
그러면 짜잔~! 우측에 셋톱 아이디의 중복 제거 합산 값 컬럼이 추가됩니다.
열심히 만든 시각화 화면을 다음에 또 쓰고 싶으면 저장하고 다음에 다시 볼 수 있습니다. 여기까지 KIBANA로 데이터 시각화하는 방법을 알아보았습니다.
마무리하며
만약 다른 데이터와 합쳐야 하면 키바나에서 csv 파일을 추출한 후 엑셀에서 vlookup을 돌립니다. 이런 경우가 꽤 자주 발생하므로 키바나로만 최종 데이터를 추출하기는 어렵습니다.
저에게 데이터를 분석하는 스킬이 또 쌓이면 한 번 더 업데이트된 버전으로 데이터 분석 방법에 관한 글로 찾아올게요! 지금까지 긴 글 읽어주셔서 감사합니다. :)
같이 읽으면 좋은 글:
서비스 기획자라면 꼭 알아야 하는 "이것"
그리고 "이것"이 필요한 세 가지 이유 | Q. "이것"은 무엇일까요? 1. 좋은 기획자는 "이것"이 어디에 있는지 알고 있습니다. 2. 기획의 근거와 성과가 모두 "이것"에 있습니다. 3. 기획의 구조도 "이것
brunch.co.kr
'서비스 기획 > ✏️ 서비스 기획' 카테고리의 다른 글
| "나도 API 안다고!" 2: 재밌는 API 실습하기 (0) | 2021.10.22 |
|---|---|
| "나도 API 안다고!" 1: API 5분안에 이해하기 (0) | 2021.10.22 |
| 서비스 기획자로 취업/생존하는 방법 Q&A (2) | 2021.09.27 |
| 서비스 기획자에게 도움이 되는 블로그 2편 (1) | 2021.09.27 |
| 서비스 기획자라면 꼭 알아야 하는 "이것" (0) | 2021.07.25 |




댓글